

Деякі помилки в SEO - критичні. Вони зводять нанівець всі зусилля з пошукового просування. Одна з таких помилок - дубльовані сторінки. Пропущені оптимізатором клони вкрай негативно сприймаються пошуковими системами та скочують сайт на задвірки видачі. Тому так важливо виявити дублі вже на перших етапах SEO перевірки сайту і швидко їх усунути. Як це зробити - розповімо в сьогоднішній статті.
Що таке дублі сторінок?
Дублі - це різні сторінки сайту з унікальними URL, контент яких повністю або частково збігається.
В межах одного ресурсу можуть перебувати такі типи дублів:
- клони з ідентичним HTML-кодом;
- з дубльованим вмістом блоку <body>;
- копії Title;
- дублікати Description;
- однакові H1.
Більшість оптимізаторів розглядають два основних типи SEO дублів сторінок - повні і часткові дублі.
Повні дублі
Це абсолютні клони, сторінки з повністю ідентичним вмістом, доступні за унікальним веб-адресами.
Це можуть бути:
- ідентичні сторінки зі схожими URL, але один прописаний з "www", а інший - без:
http//www.site.ua; http//site.ua. - ідентичні сторінки зі схожими URL, але один прописаний з html, а інший - з https:
https//site.ua; http//site.ua. - клони, згенеровані через реферальні посилання. Реферальне посилання - це посилання з персональним ідентифікатором, за яким веб-сайти визначають, звідки прийшов новий відвідувач.
- зміни в ієрархічній структурі адрес, через які створюються клони. Наприклад, так товар може бути доступний під кількома адресами:
http://site.ua/catalog/dir/product;
http://site.ua/catalog/product;
http://site.ua/product. - адреси веб-сторінок в нижньому і верхньому регістрах:
http://site.ua/news/;
http://site.ua/NEWS/;
http://site.ua/News/. - некоректно налаштована сторінка 404, генеруюча дублікати;
- перша сторінка пагінації каталогу, якої бути не повинно:
http://site.ua/catalog/page1. - копії сторінок зі слешем / без слешу в кінці URL:
http://site.ua/catalog///tovar;
http://site.ua/catalog//////tovar.
И так далі.
Часткові дублі
Часткове дублювання контенту на сайті - це сторінки, які повторюють частину вмісту інших, але не є абсолютними клонами. Причиною їх виникнення найчастіше стають особливості системи управління сайтом.
Найчастіше частковими клонами виступають:
- Дублі, згенеровані сторінками фільтрів, пагінації та фільтрів. Наприклад, коли користувач використовує фільтр товарних позицій, URL трохи змінюється, і боти пошукових систем індексують цю сторінку як окрему. Але контент на сторінках не змінюється.
- Блоки описів і коментарів. Ситуація практично аналогічна попередній: перехід до блоку коментарів або відгуків генерує додатковий параметр в URL, але сторінка залишається тією ж.
- Друк для завантаження. Такі сторінки повністю повторюють вміст сайту. Наприклад: http://site.ua/news/new1 и http://site.ua/news/new1/print.
В такому випадку пошук дублів сторінок дещо ускладнюється. При цьому наслідки їх наявності мають системний характер і погано відбиваються на позиціях у видачі. Як саме? Розглянемо далі.
До чого призводять дублі
Наслідками великої кількості клонів стають:
- Проблеми з попаданням важливих сторінок в індекс. "Подорожуючи" марними сторінками, боти Google і Яндекс даремно витрачають краулінговий бюджет (кількість сторінок, яку бот може відвідати в межах одного візиту). Неважливі і навіть шкідливі для ранжирування сторінки потрапляють в індекс, в той час, як необхідні залишаються поза ним і не потрапляють в видачу.
- Пошуковий алгоритм може порахувати, що сторінка дубля більш релевантна запиту, ніж пріоритетна сторінка. В такому випадку в видачу потрапить саме дубль. Ну або в неї не потрапить жодна зі сторінок.
- Зниження посилальної ваги пріоритетних сторінок. Вага сторінок ресурсу - це своєрідний рейтинг, критерієм якого стає кількість і якість посилань на ці сторінки. Наявність клонів призводить до того, що посилальна вага розподіляється між ними, послаблюючи позиції пріоритетної сторінки. Таким чином, всі витрати на закупівлю і розміщення зовнішніх посилань виявляються марними.
- Погіршення ранжирування всього сайту в Google і Яндекс через наявність неунікального контенту.
Одне з основних вимог пошукових систем до сайтів: одна сторінка = одна URL-адреса = унікальний контент на сторінці. Дублі руйнують цю формулу. Тому, щоб уберегти сайт від втрати трафіку та існування на задвірках видачі, важливо перевірити сайт на повторювані посилання і дубльований контент вже на першому етапі оптимізації та по ходу просування. Як це зробити – розповімо далі.
Як виявити дублі сторінок
Ось кілька ефективних методів пошуку дублів:
- ручний моніторинг;
- пошук через панелі веб-майстра;
- перевірка ресурсу за допомогою онлайн-сервісів;
- використання десктопних програм.
Моніторинг видачі вручну
Отже, як перевірити сайт на дублі сторінок за допомогою ручного моніторингу? Вводимо в рядку пошуку запит в такій формі:
site: назва ресурсу пробіл фрагмент тексту
Обсяг введеного тексту не повинен перевищувати одне речення, яке не повинне закінчуватися крапкою.
У відповідь на запит з'являться всі сторінки з цим текстом на вашому ресурсі. Виявити повні дублі допоможе текст сніпету: якщо фраза з запиту виділена жирним шрифтом у двох і більш сніпетах з видачі - значить дублі мають місце.
Пошук через Google Search Console
Google Search Console допоможе виявити дублі сторінок з ідентичними мета-описами і заголовками TITLE. Для цього необхідно перейти на вкладку «Оптимізація» - «Оптимізація HTML». Так ми отримуємо список потенційних клонів.
Онлайн-сервіси
Найчастіше перевірка дублів сторінок пошуковими оптимізаторами здійснюється за допомогою наступних онлайн сервісів:
- serpstat.com
- seoto.me;
- jetoctopus.com.
Розглянемо специфіку роботи з кожним із сервісів.
Serpstat
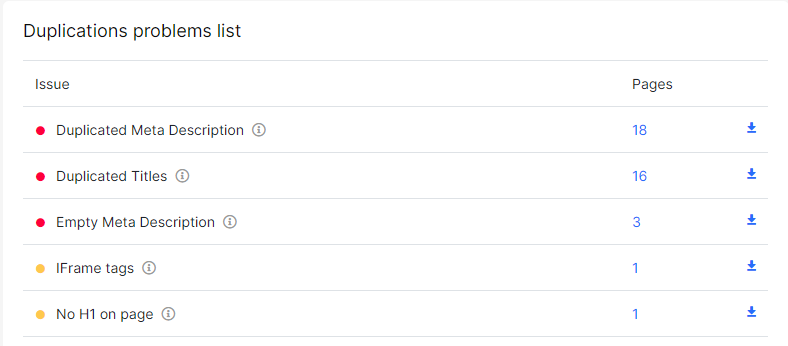
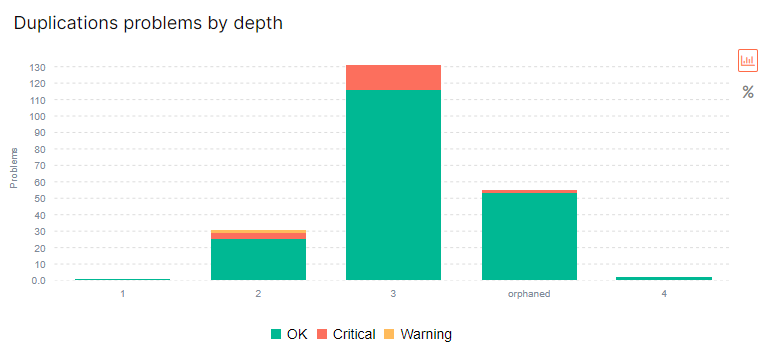
За допомогою сервісу можна провести технічний SEO-аудит ресурсу і виявити більше 20-ти типів помилок. У їх числі - пошук дубльованого контенту на двох і більше сторінках. Платформа виявить:
- повторювані заголовки Title;
- копії Description;
- дубльовані H1;
- повне повторення заголовків h1и Title;
- наявність клонованих текстів і сторінок.


Платформа надає безкоштовний функціонал і розширені можливості за підпискою.
Seoto.me
Платформа також дозволяє виявити помилки на сайті, в тому числі й дублі. Для цього необхідно зареєструватися на сайті, додати проект (безкоштовно для трьох проектів, більше - за невелику плату) і запустити сканування веб-ресурсу.
JetOctopus.com
Сервіс працює за схожим принципом, проте допомагає виявити, також, і смислові дублікати. Це сторінки зі схожим, але унікально прописаним контентом.

Платформа пропонує безкоштовну пробну версію, і подальше користування за обраним тарифним планом.

Десктопні програми парсингу
Програми парсингу - це одна з найбільш частих рекомендацій щодо того, як знайти дублікати сторінок на сайті пошуковому оптимізаторові.
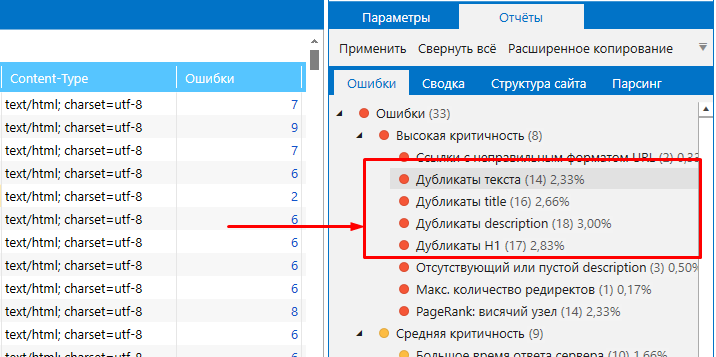
Netpeak Spider допоможе провести повний аудит ресурсу і виявити 62 помилки в 54 параметрах, серед яких - дублі. Шляхом сканування можна знайти сторінки з клонованим змістом: повні дублі, копії сторінок за контентом блоку <body>, дубльовані теги «Title» і метатеги «Description».

Підходить навіть для великих проектів.
Screaming Frog Seo Spider використовується для невеликих і середніх веб-ресурсів. Десктопна програма сканує сайт на наявність повних і часткових дублів, повторюваних назв, заголовків, мета-даних.
Безкоштовна програма Xenu Link Sleuth також проводить техаудит і знаходить повні копії, в т.ч. і заголовків. Однак, фрагментні дублі вона не виявляє.
Перед тим, як дізнатися кількість сторінок на сайті, необхідно встановити програму, прописати адресу сайту в рядок введення, провести сканування, в напівавтоматичному режимі впорядкувати результати та порівняти збіги.
Пам'ятайте, що перевірка на наявність дублів - це лише половина справи. Після виявлення помилок їх необхідно усунути.
Як усунути дублі
Отже, підходимо до завершального етапу: як прибрати дублікати пріоритетних сторінок? Методів кілька.
Найбільш очевидний - видалити клони сторінок зі слешем і іншими фрагментами URL, які генерують дублі. Також можна заборонити роботам додавати в індекс копії, вписавши відповідні умови в файл "robots.txt". Цей метод актуальний для службових сторінок, які повторюють контент основних.
Ще одне рішення - налаштувати 301 редирект зі сторінки-дубля на пріоритетну сторінку сайту. Це допоможе з помилками в ієрархії розділів і reff-мітками.
З налаштованим 301 редіректом роботи бачать, що за конкретною адресою сторінка більше не доступна і перенесена на інший URL. Так вага з дубльованої сторінки перенаправиться на пріоритетну.
Також видалення дублів можна здійснити, проставивши тег "rel=canonical". Це вирішить проблему з пагінацією, угрупованнями та фільтрами.
А якщо проблема пов'язана з версіями для друку і блоками з коментарями та відгуками, скористайтеся тегом:


Це дозволить приховати подібні блоки від роботів пошукових систем.