Статьи про SEO





Мы свяжемся с вами в ближайшее время!

Работа с ядром или SEO-семантика — это рутинная работа. Формирование семантического ядра — это сведение большого объема исключительно релевантных поисковых фраз в единую, логически построенную таблицу. Чистка и структурирование ключей — это трудозатратная задача, которую, впрочем, можно значительно облегчить. Для этого нужно освоить актуальные для поисковых оптимизаторов возможности таблицы Google, которые позволят ускорить и облегчить обработку данных без дополнительных платных инструментов.
Семантическое ядро состоит из сотен, иногда тысяч, а иногда и десятков тысяч запросов — в зависимости от масштаба веб-ресурса и конкуренции в тематике.
Для того чтобы составить полное семантическое ядро, нужно собрать маркерные, основные запросы. Высоко-, средне- и низкочастотные.
Потом на их базе создать расширенные группы запросов при помощи синонимов и фраз, схожих по смыслу. Все это делается в полуавтоматическом режиме при помощи специальных сервисов.
Конечно, при сборе ключей неизбежно косвенное или прямое их повторение, попадание спецсимволов в списки, слов с прописными буквами, фраз с лишними пробелами и т.д.
Их все необходимо фильтровать. Плюс находить и исключать из списка мусорные — бесполезные для продвижения слова.
Все эти действия — это сложная и трудоемкая работа с таблицами и списками. Благо, формулы Google таблиц помогут ускорить операции и даже спарсить содержимое тегов с посадочных страниц.
Рассмотрим самые полезные.
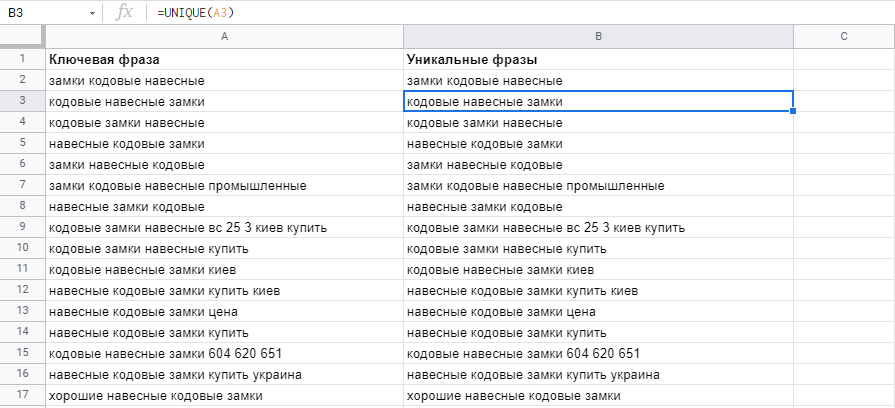
Позволяет отфильтровать дубли из списка. Например, если вы собрали ключи из разных источников. Для ее применения в первой ячейке соседствующего со списком ключей столбца вбиваем:
=UNIQUE(диапазон)
Во втором столбце формула, сохраняя очередность, выкатит список уникальных ключевых фраз, отфильтровав повторения.
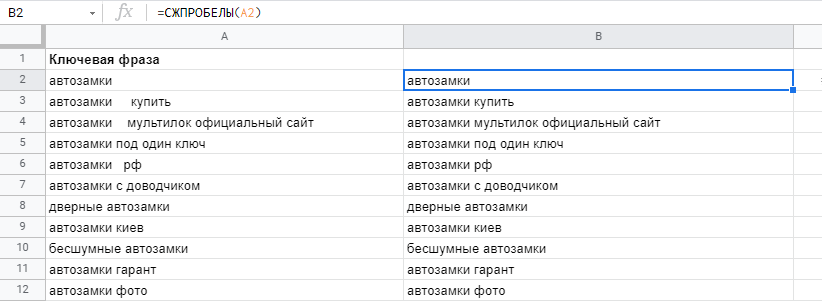
Формула помогает быстро устранять случайные пробелы, проставленные перед и после ключевой фразы. Учтите, что пробелы, в том числе и лишние, между словами остаются.
Формула выглядит следующим образом:
=TRIM(прорабатываемый диапазон)
Чтобы быстро очистить всю таблицу от таких помарок, используйте формулу СЖПРОБЕЛЫ, скопируйте столбец с примененной формулой и вставьте в чистый столбец сочетанием клавиш Ctrl+Shift+V (без форматирования).
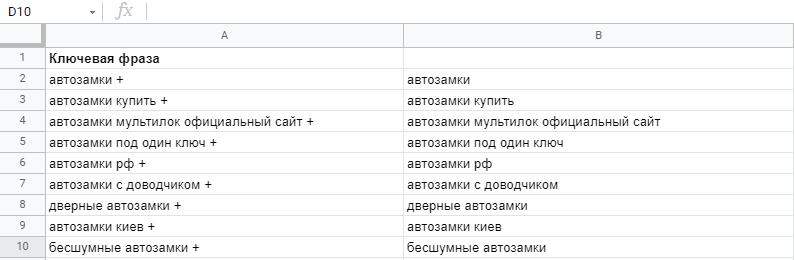
После парсинга семантики из сторонних ресурсов или онлайн-сервисов в список ключей попадают не только ячейки с лишними пробелами, но и лишними символами. Плюсики, кавычки и т.д. Функция позволит автоматически удалить такие символы и выгрузить ключевые фразы в чистом виде.
Как вводится формула:
=ПОДСТАВИТЬ(ячейка; фрагмент текста для замены; на что заменить)
Если вам нужно просто убрать лишние символы, в аргументе «на что заменить» ставим "". Пустые кавычки.
Как это выглядит на примере:
=ПОДСТАВИТЬ(В4; «+„; “»;)
Здесь:
Как заменить символы сразу для всего списка:
Так мы получим список очищенных ключей без применения на них формулы.
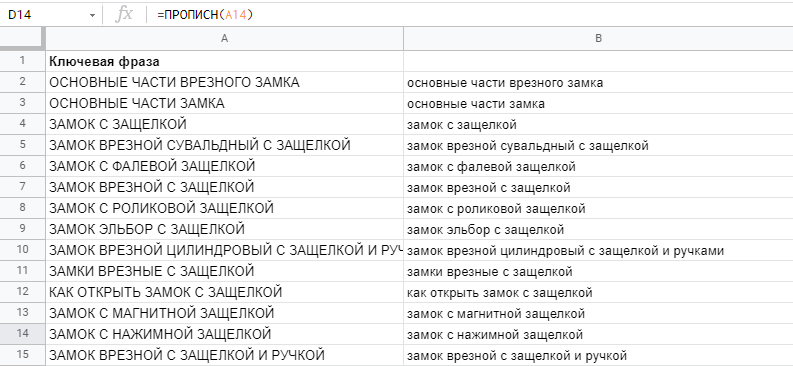
После парсинга ключей из разных источников, например, сайтов конкурентов, в список могут попасть слова, написанные с заглавной буквы. Для унификации семантики важно перевести все буквы из верхнего в нижний регистр.
В этом поможет формула СТРОЧН или LOWER.
Как мы это делаем:
ЗАМЕНИТЬ – делаем первую букву заголовка заглавной
Формула выглядит следующим образом:
=SPLIT(ячейка;"разделитель")
Задача этой функции Google таблицы в SEO, например – это разделить URL на доменное имя и расширение. Или же разделить URL страниц сайта на элементы по колонкам для того, чтобы получить список названий этих страниц.
Разделителем может служить любой пользовательский символ. При работе с адресами это, как правило, точка и слэш. При этом указанный символ разделителя возвращен не будет.
Формула ищет все значения с заданными нами условиями.
В аргументах мы прописываем диапазон и условия, которым должны соответствовать найденные ячейки. Чаще всего она применяется для поиска ключей с определенной частотой.
Например, нам нужны ключи из списка с частотностью от 20 до 50 просмотров в месяц.
Что мы делаем:
У нас должна получиться примерно такая формула:
=FILTER (A2:B;B2:B>=20;<=50)
В результате получим список ключевых словоформ с заданной частотой.
Еще одна функция, призванная помочь поисковому оптимизатору или вебмастеру быстро находить необходимые строки в крупном массиве данных.
Выглядит формула так:
=SEARCH("объект поиска";диапазон поиска)
Она полезна при выполнении разных задач. Например:
Например, у нас есть перечень ключевых фраз для интернет-магазина ножей. Мы хотим отыскать все запросы с упоминаем бренда и выделить их в таблице. Для этого используем формулу:
=SEARCH("knauff";A1)
Но! Это еще не все! На данном этапе мы получим не совсем то, что ожидали. В ячейках с ключами, в которых нет искомого слова (в нашем случае "knauff"), будет отражаться #VALUE!. А в ячейках с искомым словом — номер символа, с которого начинается это слово.
Для корректного отображения необходимо дополнительно использовать формулы с IF и IFERROR:
=IFERROR(IF(SEARCH("knauff";A1)>0;"бренд";"нет данных"))
Упомянутые функции мы рассмотрим далее.
Формула помогает установить нужное значение в ячейку при наличии ошибки. Как в предыдущем примере.
Выглядит она следующим образом:
=IFERROR(формула, выдающая ошибку;"заданное значение")
Вместо #VALUE! получим значение “нет данных”.
Функция определяет истинность логического выражения и выводит два соответствующих значения: одно для истинного, другое — для ложного.
Формула выглядит следующим образом:
=IF(логическое_выражение;"значение_истина";"значение_ложь")
Функция производит несложные вычисления и помогает при решении целого ряда SEO-задач.
Выражение может принимать любую форму, когда нужно определить логическую сообразность тех или иных условий.
Пример:
У вас есть перечень ключевых запросов с указанием частотности.
Есть цель – занять вершину топа.
Для ее достижения вам нужно выбрать из общего перечня только те ключевые словоформы, которые могут привести не менее 700 посетителей на сайт за месяц.
Что мы делаем:
Выглядеть это будет так:
= IF(В2*0.15>=;"1";"0″)
В итоге единицей у нас будут обозначены нужные ключи, а нулем — бесполезные для нашей задачи.
Формула находит ключевые запросы в первой колонке диапазона и возвращает значение указанной ячейки в найденной строке.
=VLOOKUP(запрос;диапазон;номер_столбца;[сортировка])
При помощи формулы можно, к примеру, найти уникальные, неповторяющиеся ключи, собранные в нескольких источниках. Или определить, какие страницы сайта индексируются в одной поисковой системе, но не индексируются в другой.
Формула, связке с XPath парсит данные из источников в формате XML, HTML, CSV, TSV, а также RSS и ATOM XML.
Функция применяется для широкого ряда задач. Работая с семантическим ядром, её можно использовать, например, для парсинга мета-тегов и заголовков с конкурирующих ресурсов для формирования маркерных запросов.
В поисковой оптимизации семантика — это, порой, тоскливая трудоемкая работа, нелюбимая, пожалуй, всеми. Но функции Google-таблиц, если их освоить ускоряют и упрощают обработку семантических данных. Их можно комбинировать, адаптировать под специфику проекта и поставленных задач.
При работе с семантическим ядром их можно использовать для:
Есть еще множество формул, которые пригодятся SEO-специалисту или контекст-менеджеру для работы с мультиязычными проектами, подготовки рекламных текстов, чистки ключей и т.д. Но указанные в нашей статье можно считать базовыми и наиболее распространенными.
Мы свяжемся с вами в ближайшее время!
Ми зв'яжемося з вами найближчим часом!