Статьи про SEO





Мы свяжемся с вами в ближайшее время!

Некоторые ошибки в SEO – критичны. Они сводят на нет все усилия по поисковому продвижению. Одна из таких ошибок – дублированные страницы. Пропущенные оптимизатором клоны крайне негативно воспринимаются поисковиками и скатывают сайт на задворки выдачи. Поэтому так важно обнаружить дубли уже на первых этапах SEO проверки сайта и быстро их устранить. Как это сделать — расскажем в сегодняшней статье.
Дубли — это разные страницы сайта с уникальными URL, контент которых полностью или частично совпадает.
В пределах одного ресурса могут находиться такие типы дублей:
Большинство оптимизаторов рассматривают два основных типа SEO дублей страниц - полные и частичные дубли.
Это абсолютные клоны, страницы с полностью идентичным содержимым, доступные по уникальным веб-адресам.
Это могут быть:
И так далее.
Частичное дублирование контента на сайте – это страницы, которые повторяют часть содержимого других, но не являются абсолютными клонами. Причиной их возникновения чаще всего становятся особенности системы управления сайтом.
Чаще всего частичными клонами выступают:
В данном случае поиск дублей страниц несколько усложняется. При этом последствия их наличия носят системный характер и плохо отражаются на позициях в выдаче. Как именно? Рассмотрим далее.
Следствием большого количества клонов становится:
Одно из основных требований поисковиков к сайтам: одна страница = один URL-адрес = уникальный контент на странице. Дубли разрушают эту формулу. Потому, дабы уберечь сайт от потери трафика и существования на задворках выдачи, важно проверить сайт на повторяющиеся ссылки и дублирующийся контент уже на первом этапе оптимизации и по ходу продвижения. Как это сделать – расскажем далее.
Вот несколько эффективных методов поиска дублей:
Итак, как проверить сайт на дубли страниц при помощи ручного мониторинга? Вводим в строке поиска запрос в следующей форме:
site:название ресурса пробел фрагмент текста
Объем вводимого текста не должен превышать одно предложение и не заканчиваться точкой.
В ответ на запрос появятся все страницы с этим текстом на вашем ресурсе. Обнаружить полные дубли поможет текст сниппета: если фраза из запроса выделена жирным шрифтом в двух и более сниппетах из выдачи - значит дубли имеют место.
Google Search Console поможет обнаружить дубли страниц с идентичными мета-описаниями и заголовками TITLE. Для этого необходимо перейти на вкладку «Оптимизация» – «Оптимизация HTML». Так мы получаем список потенциальных клонов.
Чаще всего проверка дублей страниц поисковыми оптимизаторами осуществляется при помощи следующих онлайн сервисов:
Рассмотрим специфику работы с каждым из сервисов.
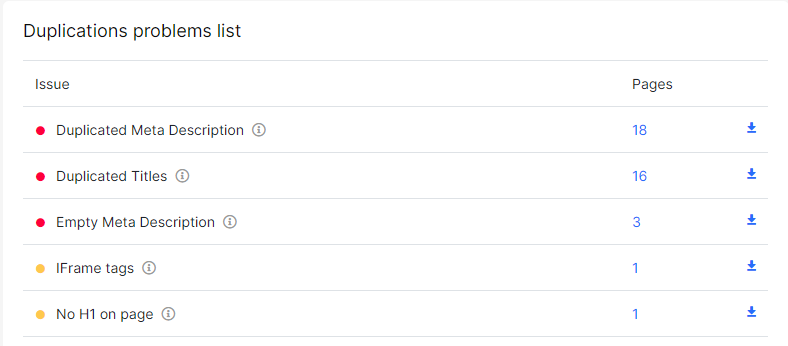
При помощи сервиса можно провести технический SEO-аудит ресурса и обнаружить более 20-ти типов ошибок. В их числе - поиск дублированного контента на двух и более страницах. Платформа обнаружит:

Платформа предоставляет бесплатный функционал и расширенные возможности по подписке.
Платформа также позволяет обнаружить ошибки на сайте, в том числе и дубли. Для этого необходимо зарегистрироваться на сайте, добавить проект (бесплатно для трех проектов, больше – за небольшую плату) и запустить сканирование веб-ресурса.
Сервис работает по схожему принципу, однако помогает обнаружить, также, и смысловые дубликаты. Это страницы с похожим, но уникально прописанным контентом.
Платформа предлагает бесплатную пробную версию, и последующее пользование по выбранному тарифному плану.
Программы парсинга – это одна из наиболее частых рекомендаций относительного того, как найти дубликаты страниц на сайте поисковому оптимизатору.
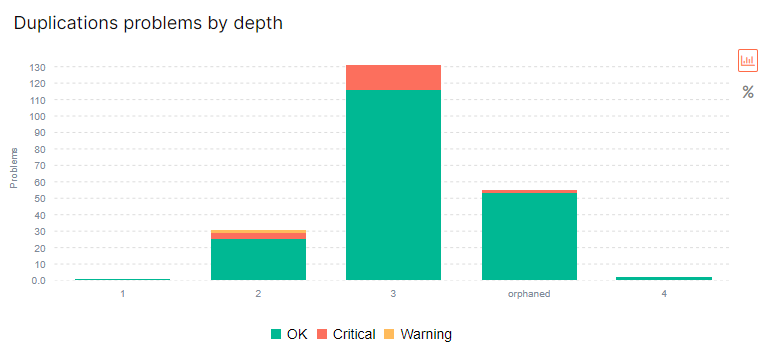
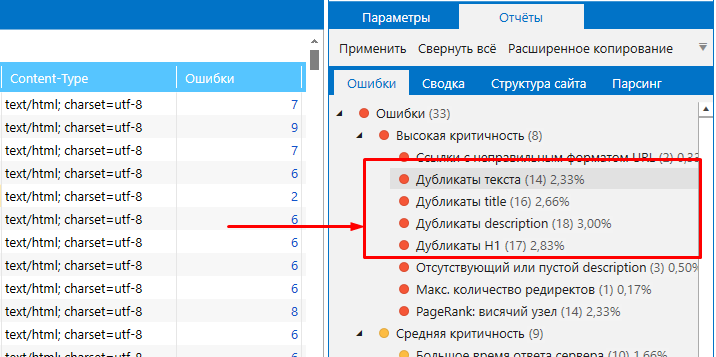
Netpeak Spider поможет провести полный аудит ресурса и обнаружить 62 ошибки в 54 параметрах, среди которых – дубли. Путем сканирования можно найти страницы с клонированным содержанием: полные дубли, копии страниц по контенту блока <body>, дублирующиеся теги «Title» и метатеги «Description».
Подходит даже для крупных проектов.
Screaming Frog Seo Spider используется для небольших и средних веб-ресурсов. Десктопная программа сканирует сайт на наличие полных и частичных дублей, повторяющихся названий, заголовков, мета-данных.
Бесплатная программа Xenu Link Sleuth также проводит техаудит и находит полные копии, в т.ч. и заголовков. Однако, фрагментные дубли она не обнаруживает.
Перед тем, как узнать количество страниц на сайте, необходимо установить программу, прописать адрес сайта в строку ввода, провести сканирование, в полуавтоматическом режиме отсортировать результаты и сравнить совпадения.
Помните, что проверка на наличие дублей - это лишь половина дела. После обнаружения ошибок их необходимо устранить.
Итак, подходим к завершающему этапу: как убрать дубликаты приоритетных страниц? Методов несколько.
Наиболее очевидный – удалить клоны страниц со слешем и другими фрагментами URL, которые генерируют дубли. Также можно запретить ботам добавлять в индекс копии, вписав соответствующее условие в файл “robots.txt”. Этот метод актуален для служебных страниц, которые повторяют контент основных.
Еще одно решение – настроить 301 редирект со страницы-дубля на приоритетную страницу сайта. Это поможет с ошибками в иерархии разделов и reff-метками.
По настроенному 301 редиректу роботы видят, что по конкретному адресу страница больше не доступна и перенесена на другой URL. Так вес с дублированной страницы перенаправится на приоритетную.
Также удаление дублей можно осуществить, проставив тэг “rel=canonical”. Это решит проблему с пагинацией, сортировками и фильтрами.
А если проблема связана с версиями для печати и блоками с комментариями и отзывами, воспользуйтесь тегом:

Это позволит скрыть подобные блоки от роботов поисковых систем.
Мы свяжемся с вами в ближайшее время!
Ми зв'яжемося з вами найближчим часом!